Open science is among European research policy priorities.
Research practices in Europe, especially surrounding data collection, are becoming increasingly open. The greater adoption of this open science approach is a priority which would facilitate knowledge-sharing and lead to further advancement of research. Open data, for example, is one of the key areas of activity, with special focus on FAIR (Findable, Accessible, Interoperable and Re-usable) data.
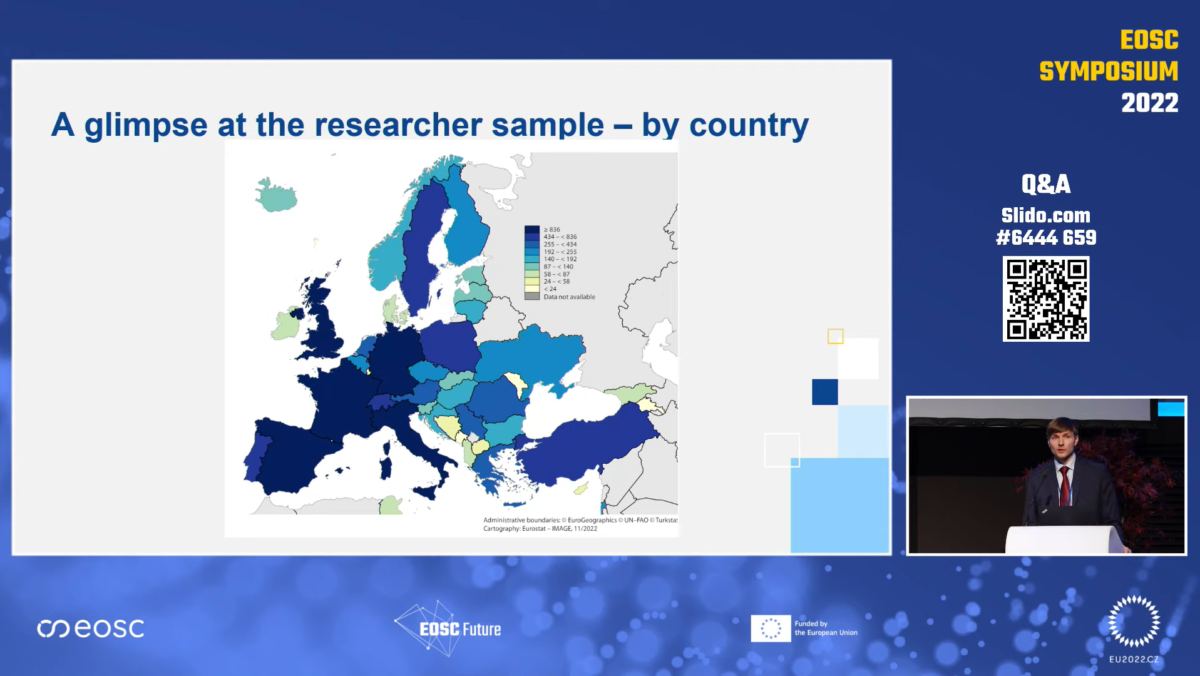
In order to better understand the current landscape of research data practices a team of Visionary Analytics, Data Archiving and Networked Services, Digital Curation Centre, and the European Future Innovation System (EFIS) Centre carried out a study of the European research data landscape contracted by the European Commission. The study covered all EU Member States, Horizon 2020 Associated Countries, and the UK. Here is what we found.
What do researchers do?
We looked at researchers’ practices in terms of the characteristics of the data they create and reuse. Most respondents worked with up to 10 GB of data, both when producing and when reusing data in their current/most recent research (70% for production, 75% for reuse). The most common types of data are experimental (64%) and observational (58%), with 83% of data overall being quantitative and 58% being qualitative.
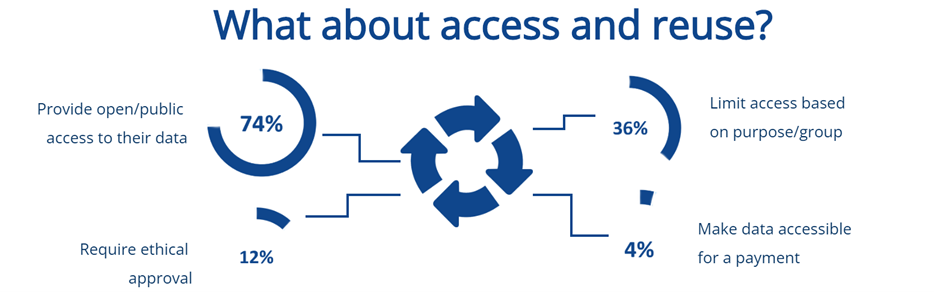
How FAIR is the data?
Most respondents (63%) indicated at least some level of familiarity with the FAIR principles. However, only 18% of respondents indicated that they are both familiar with them and put them in practice. Yet, when it comes to FAIR aligned practices, we see that more researchers engage in them than are actively familiar with FAIR. The most frequently reported FAIR-aligned practice is to look for data to reuse when starting new research.
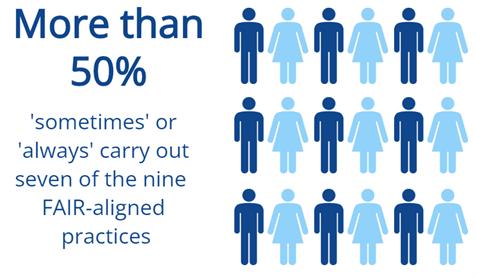
Far fewer respondents reported using repositories to share their own data, which suggests that there may be a lot less data available for reuse than there should be. The second most popular activity is developing data management plans (DMPs), with more than three-quarters of respondents indicating that they develop data management plans at least some of the time. However, when looking at the frequency of other FAIR-aligned practices such as assigning PIDs, using standards,
and depositing with repositories, it seems there may be a disconnect between what is planned and what is carried out. This could suggest that there is a need for ongoing support and feedback for data management plans over the entire lifecycle of the research project to ensure that they are both feasible and ultimately implemented.
What about research data repositories?
Using the F-UJI FAIR data assessment tool, we sampled 31 data repositories from the re3data.org registry. For each of these repositories, up to 300 datasets were randomly selected and assessed. F-UJI conducts 16 tests, which together address 11 of the FAIR principles. For each dataset, F-UJI reports the scores earned per principle, based on the associated tests performed and the maximum scores attainable. For this dataset sample, we found an overall average F-UJI FAIR score of 54.6%. 
The case studies revealed that from the repositories’ perspective, funding for operations or equipment is not a key issue, as each had the commitment of an institution or government in sustaining the repository. The key challenges reported mostly relate to the need to increase digital and data management skills among PhD students, and to support them via data stewards with combined IT competences and knowledge of the specific field of science.
Interested in learning more?
Our Research Manager Jonas Antanavičius presented these findings at the EOSC Symposium 2022 on November 16th this year. Tune in for the presentation and other data topics here! Or simply check out the full study here. If you still have questions, drop us a line!